
When you try to open a PDF file in @Voice, you will see the "PDF Text Import Settings" screen. On this screen, if you turn on the "Manually crop pages before extracting text" option, and press the "Open file" button, the app will show the first page of your PDF document. You may change pages with the slider and < > buttons on top. The following text discusses two usage scenarios:
Simple, where you only want to remove unwanted page headers and footers
Complex, if you have a multi-column PDF document, where text from columns and other fragments is extracted in wrong order.
Use pinch gesters to zoom in or out, double tap to zoom 2x or return to full view of the page.
Press and drag corners or edges of the white area to adjust its size or position.
When multiple region are defined, tap any of them to activate it (becomes white), then adjust.
To delete one of many defined extraction region, either activate it with tap and select menu - Delete, or long-press the region you want deleted.
To add a new region, either press menu - Add region (appears at top left of page), or long-press the dark page area outside of any region (appears at the place you pressed), then adjust it by dragging corners or edges.
Use the horizontal slider on top to quickly change pages, or press the round buttons with < and > symbols to go to the previous or next page.
Important functions are also on the "hamburger menu" at top-left.
The fastest way to finish work is by pressing the Back button on the phone - it still saves all the regions you defined, and proceeds to text extraction in the main @Voice app.
For each page you may move the gray area edges up and down, right and left as needed, to cut out any unwanted text, such as page numbers, headers and footers, sidebars, footnotes etc. Only the text from the white area in the middle will be included when extracting text for reading aloud. The image below shows @Voice screen, where the page headers and footnotes were cut out to leave only the interesting part of text.
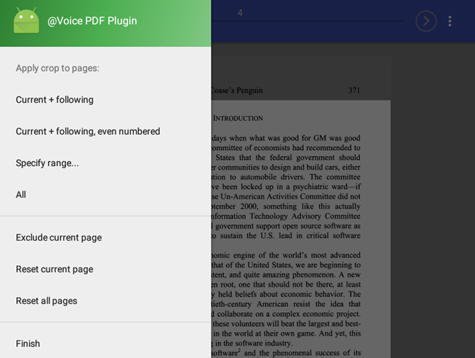
At any time you may press the "hamburger menu" button
 at top left, to show additional functions.
These functions let you to propagate current page crop to other pages, exclude
some pages completely from the text extraction process etc.
at top left, to show additional functions.
These functions let you to propagate current page crop to other pages, exclude
some pages completely from the text extraction process etc.
When finished, press the Finish item there, or the phone Back button. This will take you back to the main @Voice app, start the actual text extraction, followed by reading aloud.
Let's say we have a 2 column text in PDF, and due to the way this PDF was created, the right column text appears first when @Voice extracts it, followed by the left column. Or the text, after extraction, is a mixture of the left and right column, etc. Not very useful... In @Voice we can define multiple areas to extract text from, and set their order. Let's see an example:

On this page we don't want of course the page number and header at top left, but additionally the text from right column extracts before the left. Additionally the table at top-right interrupts the paragraph in the middle of a word, and is not useful when listening, so we'll remove it too. The big white area above means that all text would be included, if nothing is done. Let's do the column selection in WRONG ORDER first to show how to fix it later: grab the top right corner with the finger (or mouse) and move it to outline the lowe part of the RIGHT column first, and adjust similarly the low-right corner. The result is below:

Now we need to add also text from the left column. You could use the 3-dots menu at top-right to "Add region", or faster - long press near top left corner of column 1. You'll see another white rectangle added, drag its edges or corners to contain column 1 text:

Almost there, but note the numbers in the middle of each region, they show that still the text would be extracted first from the right column, then from the left. Fix it by selecting menu - Change order, then press first the left region, then right:

Page 1 of this document was more interesting - look at the result of my work on it:

I excluded the footnote on this page, as it was interrupting the paragraph flow from the right column to page 1 to the left column of page 2. Also the author name and affiliation in region 2 where placed in the PDF file at the end of this page text, again interrupting the paragraph flow, so I explicitly made this "region 2", to extract just below the title.
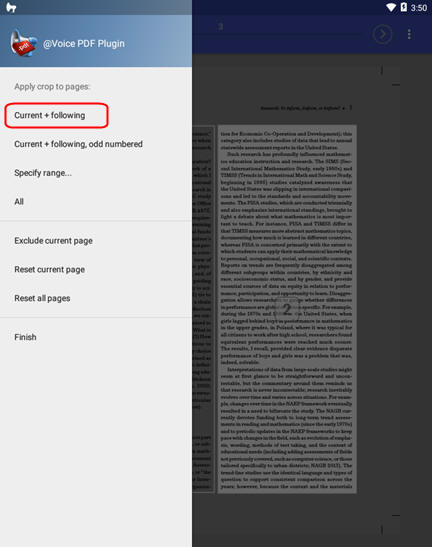
The other pages, 20-something of them starting from page 3 had identical layout, so after definining these two regions in correct order:

I pressed the "hamburger menu" at top left and chose "Apply crop to pages: Current + following", pressed Back button and after a few seconds had my article perfectly extracted for listening:
Well, happy listening to you all!
Greg